Quality Data Part 3: Cross-referenced
How I Learned To Stop Worrying And Love Common Data Entities.






This blog is part of a bigger series. We suggest starting at the start, which you can find here.
At DrugBank, we take data quality extremely seriously. When we aren’t honing our philosophies on quality, we’re inspecting our data with a fine-toothed comb to ensure each and every piece lives up to our strict standards.
Unfortunately, there’s no single metric that will deliver perfect, high-quality data. Instead, data quality is hugely dependent on the user’s needs and what they’re hoping to achieve with the data. As a result, we work tirelessly to remain flexible and responsive to changing data sources and to our users’ various needs as a way of curating better, stronger data.
Common Data Entities and Cross-references
What is it?
Our data is all organized into datasets that our users can download or access through an API. Common data entities are simply pieces of data that are shared between multiple datasets. Each common data entity increases the number of potential connections between data, and the more common data entities we have, the more highly connected and cross-referenced our data can be.
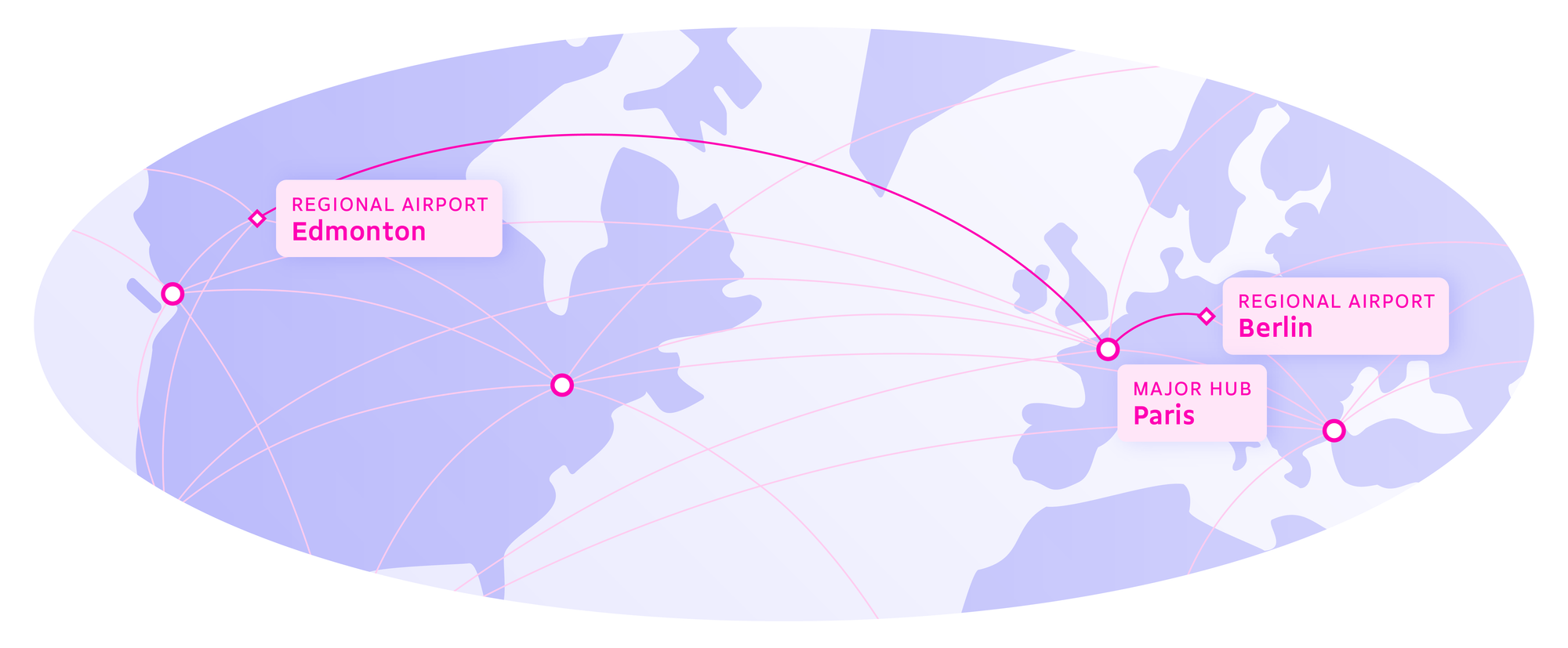
To think of this another way, common data entities are kind of like airports. There are smaller regional ones and major international hubs. The regional airports connect you to smaller cities as well as to the larger hubs, which can connect you to nearly any corner of the world. If our home base team in Edmonton wanted to get to Berlin, we might have to fly through a connecting city, such as Paris. In this analogy, the airports (Edmonton, Paris, and Berlin) would be our common data entities and each flight a vital connection between them. The major hubs would be the common data entities that have the most cross-references, whereas regional airports would be less connected data with fewer cross-references.
Well-connected hubs with ample route options makes it easier to explore more of the world faster. Similarly, well-connected data with ample common data entities makes it faster and easier to explore and learn from large amounts of data.
How do we do it?
At DrugBank, we excel at normalizing and enhancing drug data. Our team of experts work diligently to build connections between established and trustworthy external data, such as RxNorm and NDC so that our users can explore it with confidence.
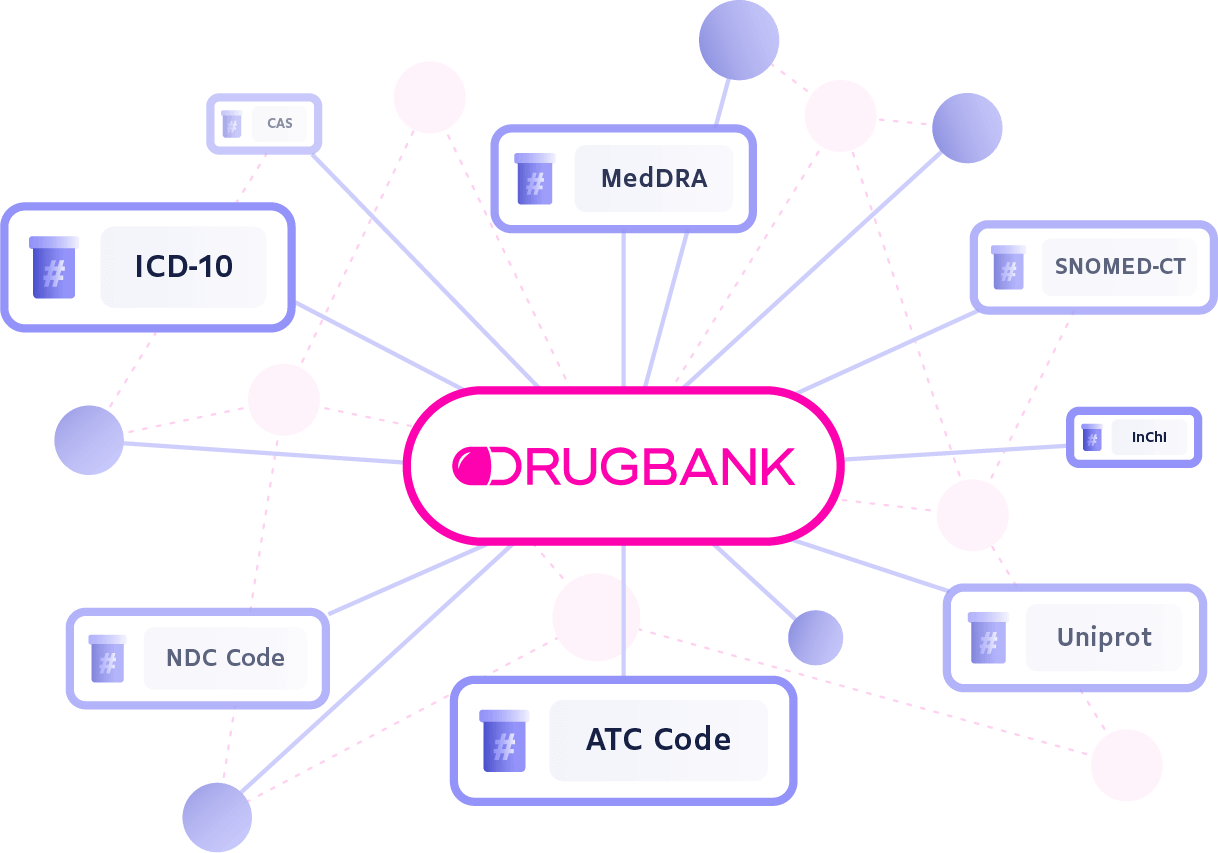
To look at a specific instance in our knowledge base, we can explore our conditions data. This structured hierarchical collection of medical terms and concepts is connected to a number of other datasets that can be used to ‘jump’ between different data points. Whenever possible, we map our conditions to external ontologies, such as SNOMED, ICD, and MedDRA, to ensure both internal and external connectivity. This way, regardless of how you handle data internally, you will always have a common means of building external connections.
We’ve also developed an in-house tool that has made cross-referencing our data easier. With it, we can help our users map our data to their existing drug data (as long as the data they’re cross referencing meets a few of our requirements). This tool was developed with the help of proprietary AI, which enables it to tolerate some level of imperfections in drug data and will find matches where traditional mapping methods typically fail. It also uses specially trained language models that do Named Entity Recognition (NER) in a scientific and pharmaceutical domain, thus automating the process of mapping raw text to common entities.

An example of this technology is search query analysis. Imagine searching: I’m looking for hotels in Berlin from May 22-25. A NER model for a service that connects users and travel resources might identify “hotels” (service), “Berlin” (location), and “May 22-25” (date range) as common entities. Once it does this, it can more easily connect that search to existing data it has on hotels in Berlin that are available on those dates. The machine learning model acts as the glue between the natural language a person would use to describe what they're looking for and the more traditional structured information that is better handled in a database.
Why should you care?
All databases will have internal connections and cross-references to some extent, but it is important to understand the degree of connectivity within the data you’re using.
If we take our airport analogy one step further and imagine that we’re travelling around the world to solve a puzzle (discover a new drug or prescribe the correct medication) and each city (common data entity) holds a clue, it would track that the quicker we can move between cities, the faster we’ll have a solution. Connectedness is what allows us to uncover novel information and insights.

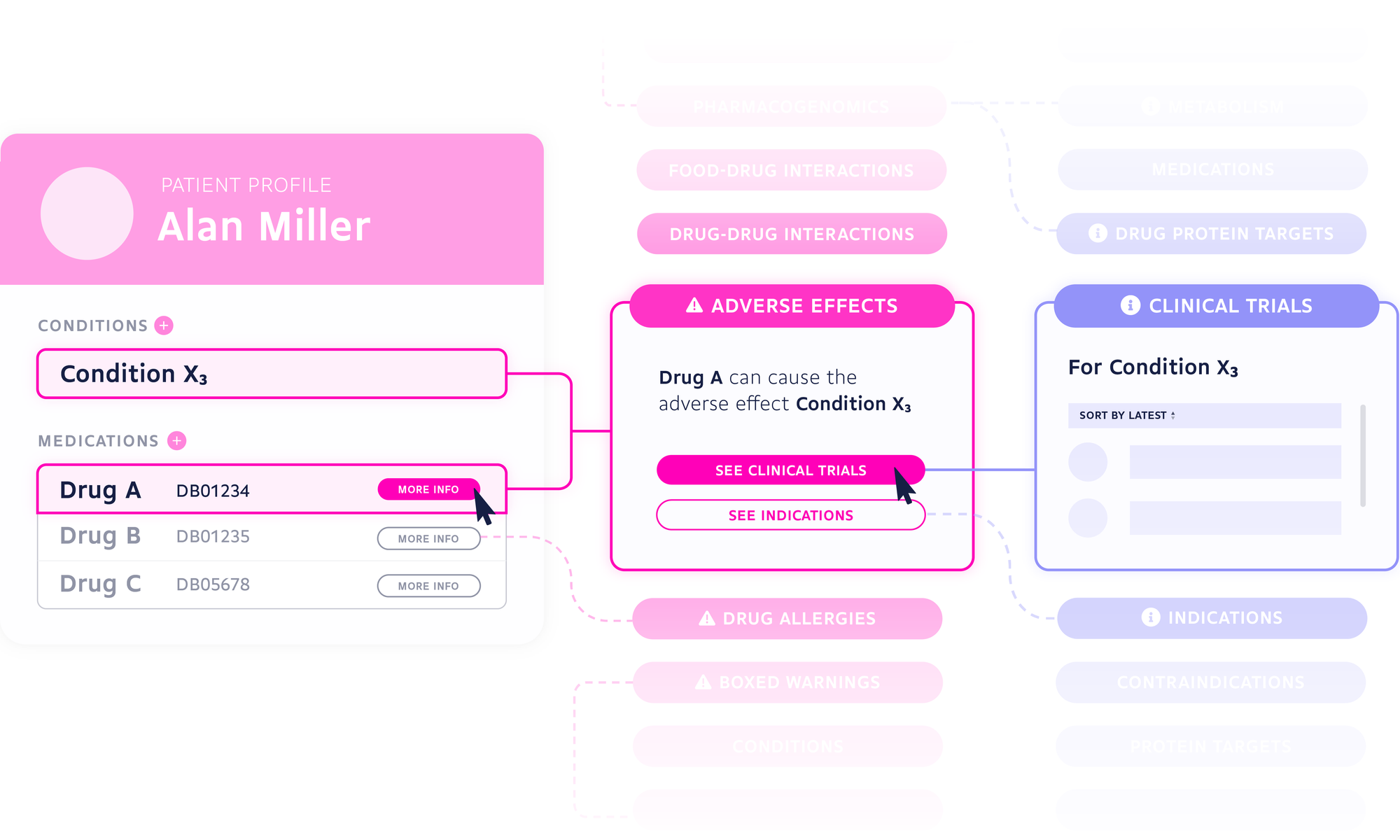
To better illustrate the power of highly connected data, imagine a patient presenting with condition X3. Utilizing our conditions data and its numerous connections to other datasets, we can explore potential causes of their condition. For example, we might want to look into the patient’s medications to search for drugs or drug products which are known to cause condition X3 as an adverse effect. Perhaps one of their medications is causing an allergic reaction, or two of their medications are interacting with each other to result in condition X3. All of these question can be explored by leveraging connections between condition X3 and other datasets.
Then we can go even further. By searching for drugs indicated to treat condition X3 (and then looking at the drug-protein targets for those drugs), we can perhaps glean the mechanism through which the condition develops. On a broader scale, this knowledge can aid pharmaceutical companies in developing new therapies (or repurposing old ones) for the treatment of condition X3.
Suppose condition X3 is rare and still poorly understood, we can still explore potential experimental treatments by examining clinical trials in which the condition is being investigated. Barring that, the hierarchical nature of DrugBank’s conditions data allows us to simply navigate up to the parent (or less specific) condition X. From here, we can explore drugs indicated for the treatment of condition X generally, rather than condition X3 specifically.
Essentially what we’re saying is that the whole is worth exponentially more than the sum of its parts. With this in mind, DrugBank has created an elaborate network of common data entities within our knowledge base. This intricate level of connectivity makes our data much more valuable than if it was merely listed and unconnected.
Final Thoughts
Assessing a dataset’s quality in terms of cross-references or common data entities comes down to more than just the existence of common connections. Instead, it is more important to ask how extensive those connections are and what you will lose if you work with data that doesn’t prioritize them. These vital hubs of data enable greater exploration, better flexibility in your work, and faster routes to uncovering insights that would otherwise be challenging, if not impossible, to make.
Check out all the blogs in this series:
Part 1: Our Philosophy
Part 2: Coverage and Consistency