Quality Data Part 6: Evidence-based, data lineage, and metadata
Because knowing your data’s history can be the difference between a big discovery and a big waste of time.





This blog is part of a bigger series. Missed part one? Check out the blog post here or Download Your Guide to Quality Drug Data to get the whats, whys, and hows of quality drug data, according to our experts.
Quality data will never be the result of a single metric or of executing on one dimension of quality perfectly. Rather, it is the sum of many crucial elements working together. Quality is also flexible depending on different users’ needs. It is for these reasons that we take into careful consideration so many elements of quality.
Evidence-based, data lineage, and metadata
What is it?
The scientific process is not linear, it is complex, messy, and requires constant re-evaluation. At DrugBank we believe that in order for data to be reliable it must represent this reality. Therefore we prioritize data that is structured in a way that models the real scientific perspective, recognizing that sometimes science gets it wrong, and that scientific findings and how we understand them will change over time.
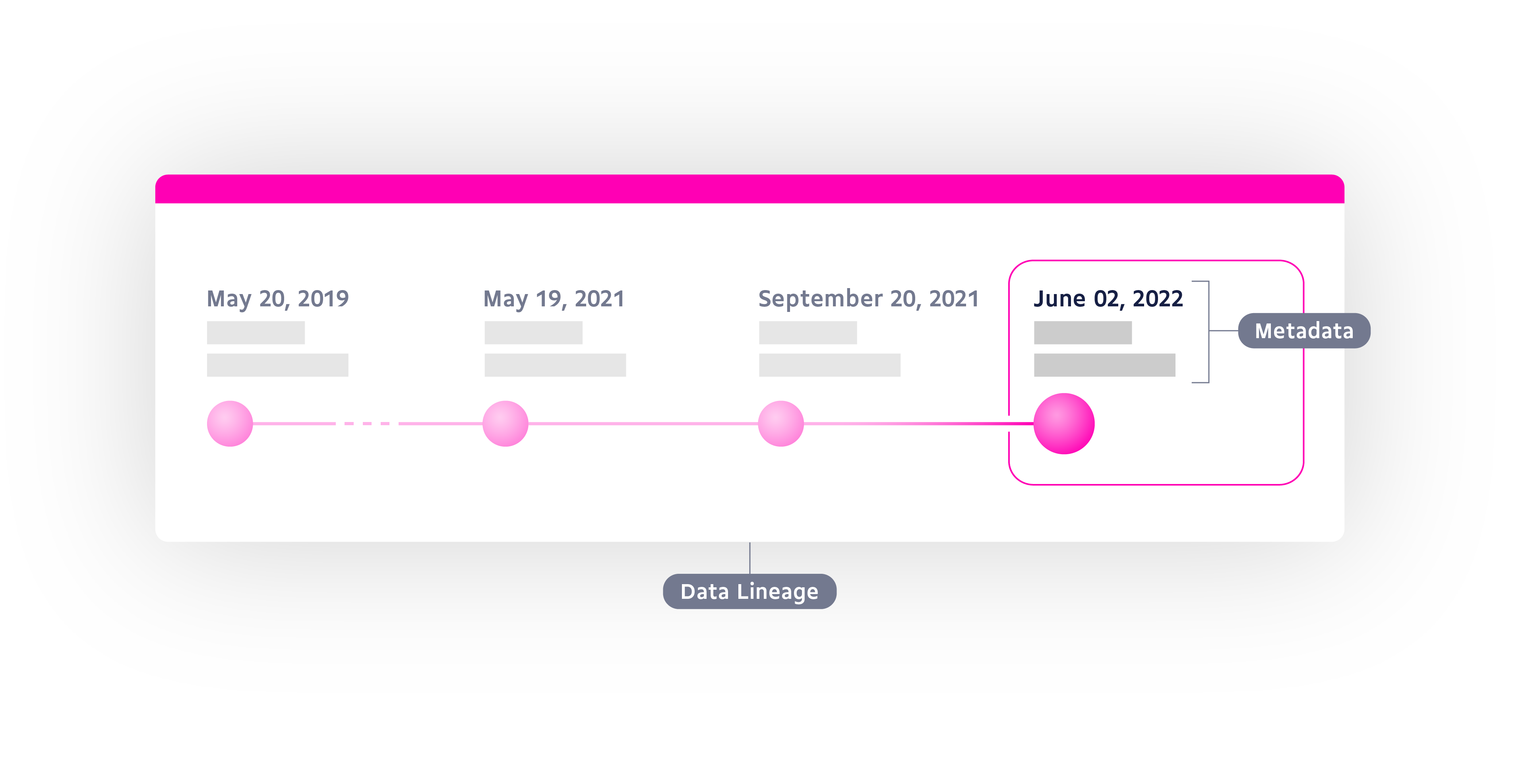
To do this we need to keep track of data changes over time and what has led to those changes, which has led us to intentionally building in data lineage to our knowledgebase. Data lineage is similar to a timeline, telling us when and where the data was created, when it was connected to other data points, where it is being used, and when big changes were made, among other things. This traceable structure makes it easier for us to understand and respond to new findings and look back to where errors may have occurred. This is where metadata, or data about data, comes in handy.
Metadata can most simply be explained as the record, references, and information about where pieces of data came from. If data lineage is our timeline, then metadata are the historical records that provide us with a more detailed background. Both of these pieces, combined with our commitment to only using data that is rooted in evidence, create a highly traceable and robust record for us and our users to rely on.
However, complications can arise when we try to define what evidence-based data is and determine what pieces of evidence to trust. Simply having references of papers that came to certain conclusions is a good starting point, but we have found that we must go beyond this. Often conclusions are disproven, discredited, or contradicted so instead we make a point to build a base of evidence that meets a certain threshold. We’ll explore this approach more in-depth in our next section.

How do we do it?
At DrugBank, we believe that decisions about traceability and data lineage must be made from an organizational perspective, and they must occur before we even begin work on our data. This ensures that our entire team is delivering the same standard of quality. For us, this can mean negotiating what a sufficient level of metadata looks like, or setting criteria for the extent or depth of information we need to validate our conclusions. We need to be able to agree on what our minimum base of evidence is ahead of our work so that only the pieces that meet or exceed those requirements are included.
Once we’ve established these metrics we can work on execution. This part of the process is where we rely heavily on our expert team of curators and data review specialists. These talented individuals work together to measure all our data against our strict standards. When seeking evidence-based data we look for recent, well-established journals, and comprehensive national clinical guidelines with information verified by clinical experts. Then we weigh these findings against our minimum base of evidence requirements to verify validity and accuracy.

If our curation team deems the data to meet our evidence requirements it will be added to our datasets and filtered into its place along the data lineage. This allows us to complete our routine data quality assurance checks, which is a review of older data to see when it was last updated and if it is still up to our curation’s standards. Data lineage also enables us to complete data quality control (which is a process of checking data origin and movement), as well as internal quality assurances (which ensures our curators are capturing data accurately and consistently according to our standards). Our hope is that in addition to building a strong dataset and knowledgebase, these processes ensure accountability for our team and deliver transparency to our users.
These same standards extend to our requirements for metadata. Within our curation practices are baked-in requirements for every single piece of data to have recorded where we derived that information. This ensures that all data in DrugBank is from the best, most reliable sources.
Why should you care?
Whether working as a researcher or a clinician, it is vitally important to have data that is strongly rooted in evidence. Quite simply, data that cannot be verified is essentially useless. Without rigorous processes and high standards in place, it can be nearly impossible to work with any level of certainty. Each conclusion or finding can quickly be drawn into question.
If, however, there is a robust system in place it creates confidence, increases safety, and improves transparency and accountability. If biases are identified in data it is much easier to look back and determine where they have come from, the impacts they’ve made, and how to course correct.

From a clinical perspective, evidence-based information is essential to confident and quick decision making and also improves the overall quality of patient care. Further yet, when time is less pressed, a thorough data lineage with ample metadata allows for an in-depth review of underlying evidence and can provide additional nuance that would otherwise be unattainable. And, as decision-making processes evolve with new knowledge, data lineage provides a way to track and learn from those advances.
As a researcher or pharmaceutical data user, reliable evidence-based data means saving time and money by avoiding missteps or incorrect findings. Users will have to suffer through fewer instances of pursuing avenues based on uncertain evidence that later is revealed to be questionable. Additionally, when we are able to maintain our organizational reputation by publishing findings that are based on solid evidence, there is much lower likelihood that those same findings will later be retracted.
Final Thoughts
This threefold dimension of quality comes down to answering the question of why. Why does this data exist and why can you trust it and rely on it to produce accurate results? By having data lineage, metadata, and evidence-based data we are able to document the scientific process which gives us some ability to identify and mitigate bias, as well as an ability to stay flexible to the shifting conclusions emerging from the biomedical world. These vital steps ensure we are always working toward maintaining the most reliable data possible.
This blog is part of a bigger series. Missed part one? Check out the blog post here or Download Your Guide to Quality Drug Data to get the whats, whys, and hows of quality drug data, according to our experts.