Quality Drug Data, Part 1: DrugBank’s Philosophy
The whats, whys, and hows of quality drug data, according to our experts.








When we say garbage in, garbage out we all know what we’re talking about. In order to make good decisions in our work and in our research we need high quality data. Without quality data we’re left making assumptions, bad decisions, and risking people’s health.
Unfortunately, quality data can be hard to come by and sometimes even harder to recognize. With the rate at which biomedical findings are being published—reports have this somewhere in the range of two million journal articles being released every year—it is increasingly more challenging to manage and maintain reliable, up-to-date data.
Should you decide to take on this herculean task yourself, there are tough questions you need to navigate. What do you include or exclude? Where do you stop? How much data do you really need? How will you keep your data up to date? And, how do you know if the data you’re collecting is accurate and evidence-based?
The challenges mount further when it comes to ambiguous and conflicting data. Now you aren’t just responsible for collecting and organizing information, you need to be knowledgeable enough to discern and interpret findings so that you can be decisive. If this is done inconsistently your work, once again, suffers.

Knowing all this, DrugBank resolved to be relentless in our pursuit of high quality data. This commitment meant laying out and adhering to the strictest criteria to ensure our data can always be trusted and relied on.
We work every day to uphold these standards by asking ourselves a series of questions.
Does it have quality coverage and is it consistent?
Coverage means knowing that our data sufficiently captures all relevant medical information while consistency focuses on how we input and maintain that data. At DrugBank we have strict curation specifications that all data must meet before it’s incorporated into our datasets. Additionally, we’ve standardized a multi-step peer review process that’s aided by automation and helps us deliver consistency and accuracy with speed.
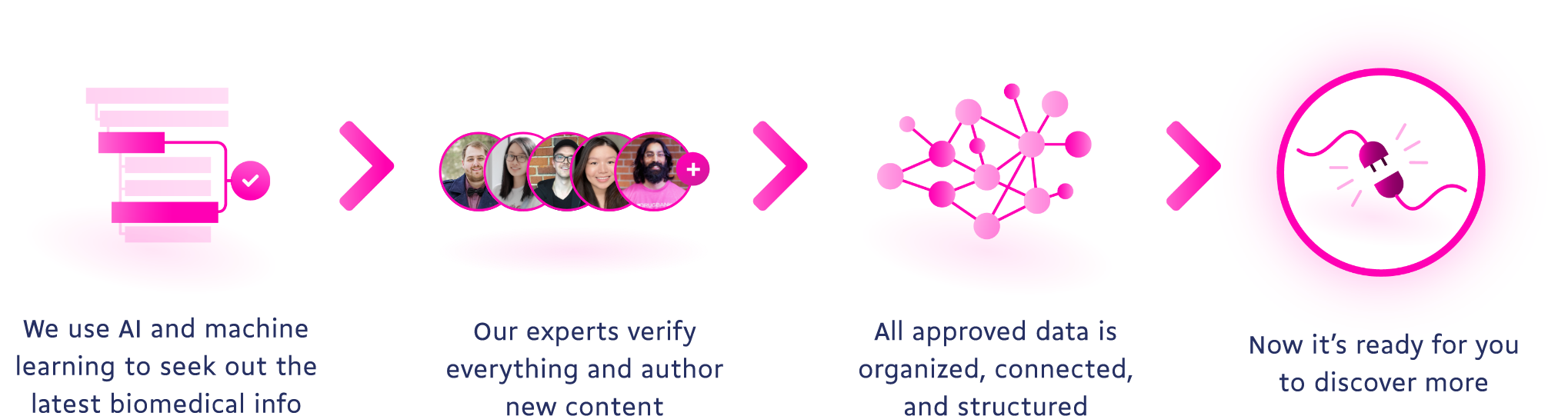
Can you cross-reference related data?
With every piece of new data we add to our datasets, we’re able to create and strengthen new connections between data points. These additional connections make our data more powerful and usable.
Is it hierarchical and flexible?
Quality data enables you to zoom in or out at the appropriate level to adapt the data to the problem you’re trying to solve. In order for our data to qualify as high-quality it needs to encompass the full variety and complexity of information available. To achieve this we incorporate as many levels of detail as possible.
How structured is it?
Structured data is easier to search, use, and reason with. We work to create highly structured, detailed data so that our users have total control over how they manipulate and explore it.
Is it evidence-based, can you follow the data-lineage, and does it have the appropriate meta-data?
Quality data is evidence-based. By ensuring that all our data is based on evidence and its lineage can be traced we are able to review and adjust our data as the underlying evidence changes over time. We also make sure that we can trace all data curation actions so that we can internally audit and question our data. At any time, we can review who added or updated data and when they did it.
Now that we’ve got good data, does it work?
Similar to any other tools or products on the market, if our data is complicated to use it’ll never be adopted and its potential can easily be lost. Once we had established strong metrics and processes for ensuring that our data is of the highest quality, we turned our focus to usability.
For us, that means offering data with a point of view. To accomplish this, our team started thinking deeply, exploring our data, and asking hard questions about our users and what they need to do their best work. We pushed ourselves to provide an exceptionally usable data structure that elegantly captures the greatest possible breadth of information without adding anything distracting or nonessential.
Then, because we know that DrugBank will never be a finished product, we created processes that cycle our team through these deep thinking phases so that we will always be growing and improving what we offer.

Data with a point of view isn’t just about how meticulously we structure our data, it's that we make intentional decisions about how we structure it. This has allowed us to build explicit relationships within our data in a consistent fashion that removes ambiguity. We obsess about the best ways to organize our data so that our users can quickly and easily start exploring and discovering more.
We also ensure that data never gets added to our knowledge base without our in-house experts verifying its accuracy and integrity. We pride ourselves on our holistic and iterative approach to building and evolving our data. Instead of recreating or deleting existing versions, we seek ways to add value to what we already have.
This pursuit for value frames how we do our work and has instilled in our team the highest sense of responsibility to continue learning and incorporating each lesson back into our systems. As a result, our team has become an invaluable resource that continues to sharpen their skills and build stronger datasets that are even more useful in the hands of our customers. The manual curation process that our experts practice takes our data beyond merely being a compilation of the world’s biomedical knowledge, and transforms it into a highly trustworthy source that has been shaped with our users’ needs in mind.

Of course there will be times when it makes the most sense to curate your own datasets. From our experience, this may be the case when your research or work is focused on a finite problem that you have a deep level of understanding about. In those instances, the amount and complexity of the data you need will be much smaller. If the scope of your work becomes much broader so too will the challenges you face. And in those instances, we’ll be here to offer you a strong foundation that you can build from.
Our database is now nearly 20 years in the making and it, and our team, has been growing and learning every step of the way. We know the importance of high-quality, highly-usable data, and we know good research and confident decisions can’t be done without it.