Quality Data Part 4: Hierarchical
In the game of quality data, hierarchies reign supreme.





This blog is part of a bigger series. We suggest starting at the start, which you can find here.
Data, and how to make ours undeniably great, is one of those things that keep us up at night. Not because we’re worried we can’t do it, but because we want to be sure we’re not missing opportunities to iterate and improve what we do. One thing that ends up being tricky is that quality is a moving target depending on who you ask.
Every user has unique needs and how they define quality will depend on how they plan to use the data. For this reason we work tirelessly to remain flexible and responsive to changing data sources and to our user’s needs. We also work to balance the many dimensions of quality data so that we are always delivering quality you can count on.
The third dimension that we take into consideration is how hierarchical our data is, so for this month we’ll be exploring what hierarchical data is and why it is such a vital piece of all quality datasets.
Hierarchical
What is it?
Hierarchies are a means of organizing information or items based on status, importance, or lineage. An obvious and very common example is a family tree. Another great example is a phylogenetic tree. This branching diagram is used to illustrate evolutionary relationships between organism, and with all life on Earth organized in a singular phylogenetic tree it is easy to trace through the evolutionary history of any known species.
Another great example is the Dewey Decimal System. Prior to its creation, books were stored in a permanent location based on when they were added to a library. Not only did this make it challenging to find specific resources, it was impossible to browse by area of interest. The Dewey Decimal System introduced a hierarchical structure that organizes resources based on 10 main classes and 10 subcategories which are broken down further into 10 additional categories. Now when you visit a library you can navigate to an area of the building that contains the topic of information you’re looking for or quickly and easily find the exact resource you need.
Hierarchies make it easy to work with large amounts of information, track connections, and identify relationships. As a result, they are also extremely useful in the biomedical field and have proven to be helpful in simplifying the complexity of biomedical data and phenomena.

How do we do it?
At DrugBank we spend a lot of time thinking about how we can best organize our data so that it brings the most value and benefit to the researchers and clinicians who rely on us every day. We lean on the organizational effectiveness of hierarchies to structure our data in a way that provides both utility and ease of use.
For every dataset we model we look for levels, groupings, and any natural hierarchies that are inherent to the data. Parent-child relationships are common, especially in biomedical data where concepts exist at varying levels of specificity. To further demonstrate this we'll take a look at two specific examples.
First, our product concepts. In its simplest form, product concepts are a hierarchical index of the many elements of a drug product. For example, a drug product may have one or more components used to treat a specific condition (ingredients), it may be available as something that can be injected or taken by mouth (route), and employ different methods of delivery, such as tablets or liquids (form). Within product concepts we’ve established levels, where each level indicates an additional piece of information that in turn makes the product concept more specific.

In this example we can see how a new property is added at every level, going from left to right. Starting with ingredient (tamoxifen), the next level adds either route (oral) or form (liquid/tablet). At the next level, both route and form are present. Finally, strengths (10mg, 20mg, 10mg/5.0mL) are added to each of the concepts in the previous level. As the level of detail increases, the product concept matches fewer products.
This is an extremely simplified version of the extensive product concept hierarchy we maintain, which can quickly end up looking quite complex. However, it is this complexity that provides users free rein to explore with very few limitations. Once expanded with all relevant concepts our product concepts end up being a much more elaborate hierarchical web.

The hierarchy of product concepts provides different degrees of granularity and allows users to search through products at whatever level of specificity is most valuable to them. This makes it much easier for our users to manipulate such complex information. It also creates a great deal of flexibility for users to search within the data, or associate our product concepts to external datasets.
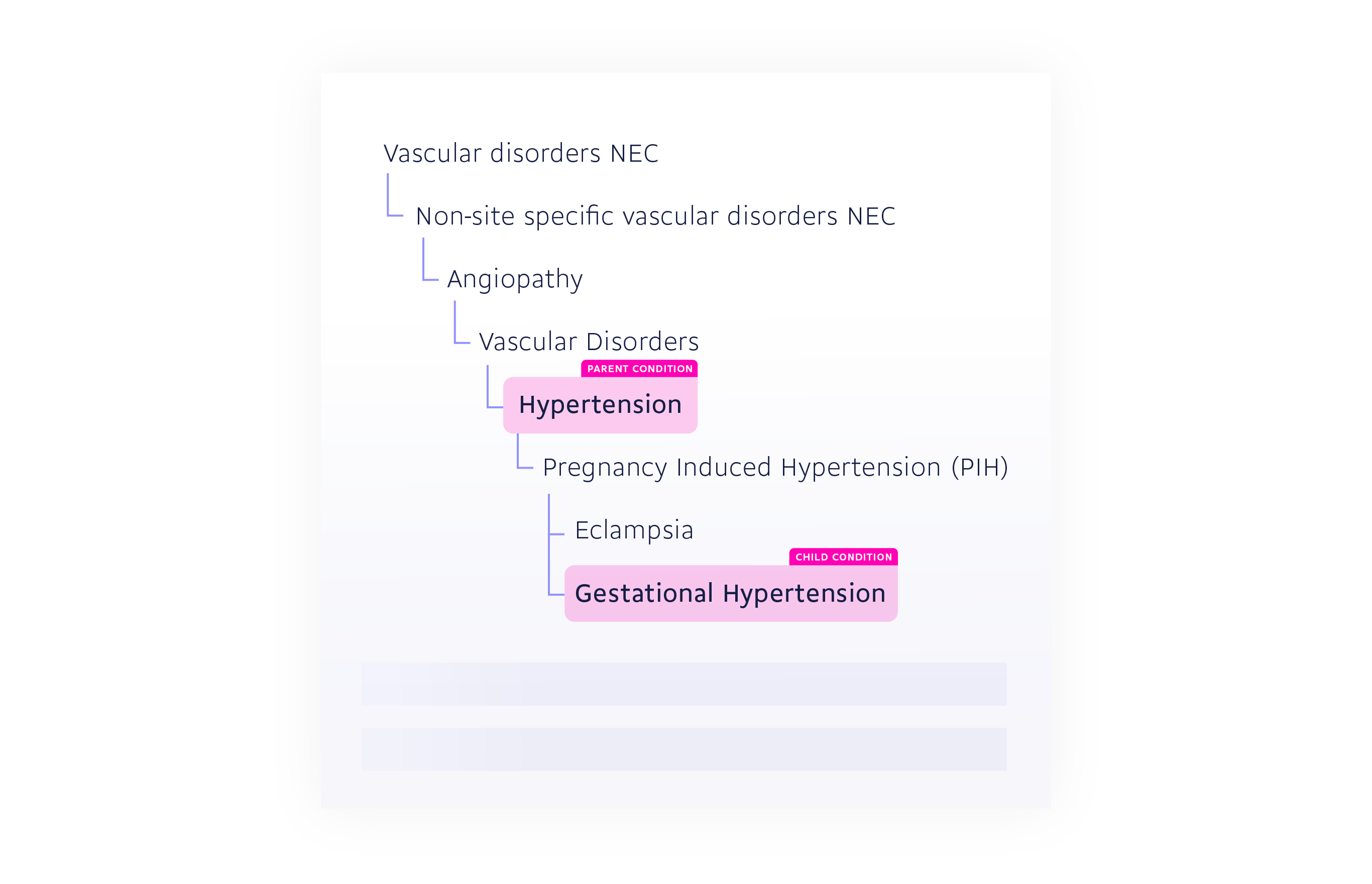
Next, we’re going to look at our use of conditions. Conditions in DrugBank represent anything related to patients or people in general. They include diseases such as asthma or hypertension, symptoms and adverse events such as headache or pain, and other characteristics relevant in a medical setting, such as weight or lab test values. Each condition is associated with a specific ID, making queries in DrugBank easier.
We organize conditions in hierarchies where each one is assigned parent-child relationships. One example of this would be the relationship between Hypertension and Gestational Hypertension, where Gestational Hypertension is a type of Hypertension, and therefore the “child” of this condition. Parent-child relationships can also be built based on combinations or modifications of conditions.
Thanks to this hierarchy, queries for conditions can be made based on the names of conditions, or more specific or general forms of those conditions.
Why should you care?
The organization of data into a hierarchical structure provides a number of benefits. Firstly, data organized in this way is intuitive. Humans (and, indeed, computers) exist in a world full of hierarchical structures, and by adopting these structures as a means of organizing data we can use the ubiquity of hierarchies to our advantage.
Let’s look at some simple data regarding drug classes to better illustrate this point.

Without any additional context or domain knowledge, we can draw several inferences from this hierarchy. For example, NSAIDs as a whole are a type of anti-inflammatory agent, as are corticosteroids, although NSAIDs and corticosteroids are distinct from one another. Similarly, we can immediately intuit that fenamates, coxibs, and oxicams are all examples of NSAIDs, but are distinct enough to each warrant their own sub-class. We could also surmise that drugs appearing within ‘Other Anti-Inflammatory Agents’ are, as you might imagine, not fenamates, coxibs, etc.

With even a quick glance, we can glean a significant amount of information by simply organizing this data into a hierarchical structure. This holds true even as the amount of data grows—as long as the hierarchy remains intact, it can handle vast amounts of data while ensuring the data contained within remains easily accessible and intuitive.
Hierarchical data is also extremely flexible. The hierarchy provides a structure within which we can view the data at multiple levels of granularity—we can zoom in to view, edit, or otherwise manipulate single pieces of data (the end points) or zoom out for larger swathes of data with ease (such as examining mid-level data points). Similarly to how the connectivity of our highly cross-referenced data makes it easy to traverse our datasets, the hierarchy of our data provides a means of exploring the different elements of a single dataset. Hierarchical organization, combined with extensive cross-referencing, provides the ultimate flexibility for our customers to navigate our data in whatever way suits them best.
Final Thoughts
If a library doesn’t employ the Dewey Decimal System there is no straightforward way to explore subject areas and serendipitously make connections that could help you see things differently. Even if you thought you knew exactly what you were looking for it could be tiresome trying to pinpoint a resource’s location. Then, if you did find the resource you were searching for, there would be no easy way to investigate related content or bridge gaps in your knowledge.
The same rules apply to data. Hierarchical structures organize data in a way that puts the power in the hands of the searcher to manipulate, explore, and make discoveries that would otherwise have been exceedingly difficult to achieve.
Check out all the blogs in this series:
Part 1: Our Philosophy
Part 2: Coverage and Consistency
Part 3: Cross-referenced